Try using a queue to keep track of exec request times. #8
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
### What changes were proposed in this pull request? This PR fixes the incorrect documentation in Structured Streaming Guide where it says `sparkSession.streams.attachListener()` instead of `sparkSession.streams.addListener()` which is the correct usage as mentioned in the code snippet below in the same doc. 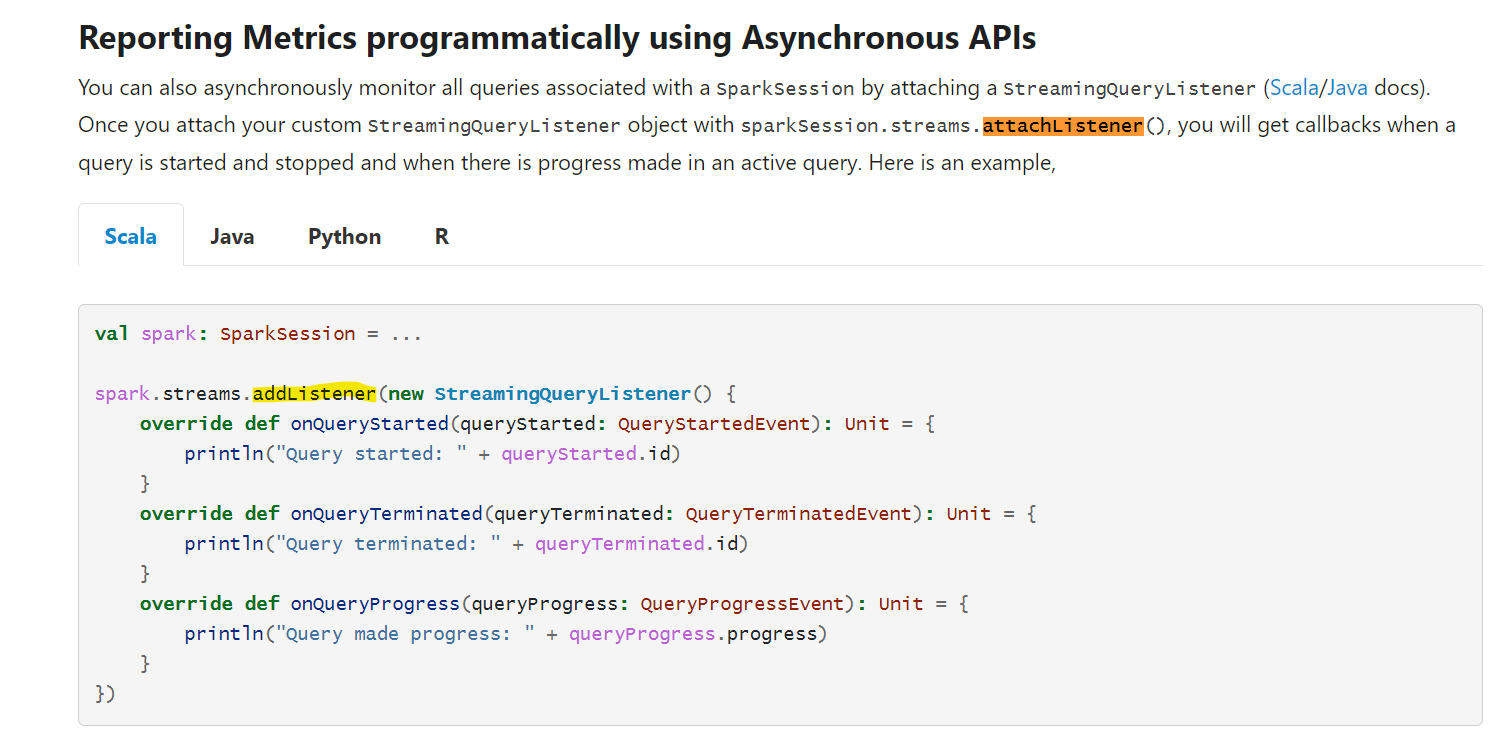 ### Why are the changes needed? The documentation was erroneous, and needs to be fixed to avoid confusion by readers ### Does this PR introduce _any_ user-facing change? Yes, since it's a doc fix. This fix needs to be applied to previous versions retro-actively as well. ### How was this patch tested? Not necessary Closes apache#35562 from yeskarthik/fix-structured-streaming-docs-1. Authored-by: Karthik Subramanian <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
{kind=link}
### What changes were proposed in this pull request?
In the PR, I propose to add new function `TIMESTAMPADD` with the following parameters:
1. `unit` - specifies an unit of interval. It can be a string or an identifier. Supported the following values (case-insensitive):
- YEAR
- QUARTER
- MONTH
- WEEK
- DAY, DAYOFYEAR
- HOUR
- MINUTE
- SECOND
- MILLISECOND
- MICROSECOND
2. `quantity` - the amount of `unit`s to add. It has the `INT` type. It can be positive or negative.
3. `timestamp` - a timestamp (w/ or w/o timezone) to which you want to add.
The function returns the original timestamp plus the given interval. The result has the same type as the input `timestamp` (for `timestamp_ntz`, it returns `timestamp_ntz` and for `timestamp_ltz` -> `timestamp_ltz`).
For example:
```scala
scala> val df = sql("select timestampadd(YEAR, 1, timestamp_ltz'2022-02-16 01:02:03') as ts1, timestampadd(YEAR, 1, timestamp_ntz'2022-02-16 01:02:03') as ts2")
df: org.apache.spark.sql.DataFrame = [ts1: timestamp, ts2: timestamp_ntz]
scala> df.printSchema
root
|-- ts1: timestamp (nullable = false)
|-- ts2: timestamp_ntz (nullable = false)
scala> df.show(false)
+-------------------+-------------------+
|ts1 |ts2 |
+-------------------+-------------------+
|2023-02-16 01:02:03|2023-02-16 01:02:03|
+-------------------+-------------------+
```
**Note:** if the `timestamp` has the type `timestamp_ltz`, and `unit` is:
- YEAR, QUARTER, MONTH - the input timestamp is converted to a local timestamp at the session time (see `spark.sql.session.timeZone`). And after that, the function adds the amount of months to the local timestamp, and converts the result to a `timestamp_ltz` at the same session time zone.
- `WEEK`, `DAY` - in similar way as above, the function adds the total amount of days to the timestamp at the session time zone.
- `HOUR`, `MINUTE`, `SECOND`, `MILLISECOND`, `MICROSECOND` - the functions converts the interval to the total amount of microseconds, and adds them to the given timestamp (expressed as an offset from the epoch).
For example, Sun 13-Mar-2022 at 02:00:00 A.M. is a daylight saving time in the `America/Los_Angeles` time zone:
```sql
spark-sql> set spark.sql.session.timeZone=America/Los_Angeles;
spark.sql.session.timeZone America/Los_Angeles
spark-sql> select timestampadd(HOUR, 4, timestamp_ltz'2022-03-13 00:00:00'), timestampadd(HOUR, 4, timestamp_ntz'2022-03-13 00:00:00');
2022-03-13 05:00:00 2022-03-13 04:00:00
spark-sql> select timestampadd(DAY, 1, timestamp_ltz'2022-03-13 00:00:00'), timestampadd(DAY, 1, timestamp_ntz'2022-03-13 00:00:00');
2022-03-14 00:00:00 2022-03-14 00:00:00
spark-sql> select timestampadd(Month, -1, timestamp_ltz'2022-03-13 00:00:00'), timestampadd(month, -1, timestamp_ntz'2022-03-13 00:00:00');
2022-02-13 00:00:00 2022-02-13 00:00:00
```
In fact, such behavior is similar to adding an ANSI interval to a timestamp.
The function also supports implicit conversion of the input date to a timestamp according the general rules of Spark SQL. By default, Spark SQL converts dates to timestamp (which is timestamp_ltz by default).
### Why are the changes needed?
1. To make the migration process from other systems to Spark SQL easier.
2. To achieve feature parity with other DBMSs.
### Does this PR introduce _any_ user-facing change?
No. This is new feature.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *QueryExecutionErrorsSuite"
$ build/sbt "test:testOnly *DateTimeUtilsSuite"
$ build/sbt "sql/test:testOnly org.apache.spark.sql.expressions.ExpressionInfoSuite"
$ build/sbt "sql/testOnly *ExpressionsSchemaSuite"
$ build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite -- -z timestamp.sql"
$ build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite -- -z timestamp-ansi.sql"
$ build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite -- -z datetime-legacy.sql"
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *SQLKeywordSuite"
```
Closes apache#35502 from MaxGekk/timestampadd.
Authored-by: Max Gekk <[email protected]>
Signed-off-by: Max Gekk <[email protected]>
### What changes were proposed in this pull request?
Adjust input `format` of function `to_binary`:
- gracefully fail for the non-string `format` parameter
- remove arguable `base2` format support
### Why are the changes needed?
Currently, function to_binary doesn't deal with the non-string `format` parameter properly.
For example, `spark.sql("select to_binary('abc', 1)")` raises casting error, rather than hint that encoding format is unsupported.
In addition, `base2` format is arguable as discussed [here](apache#35415 (comment)). We may exclude it following what Snowflake [to_binary](https://docs.snowflake.com/en/sql-reference/functions/to_binary.html) does for now.
### Does this PR introduce _any_ user-facing change?
Yes.
- Better error messages for non-string `format` parameter. For example:
From:
```
scala> spark.sql("select to_binary('abc', 1)")
org.apache.spark.sql.AnalysisException: class java.lang.Integer cannot be cast to class org.apache.spark.unsafe.types.UTF8String (java.lang.Integer is in module java.base of loader 'bootstrap'; org.apache.spark.unsafe.types.UTF8String is in unnamed module of loader 'app'); line 1 pos 7
```
To:
```
scala> spark.sql("select to_binary('abc', 1)")
org.apache.spark.sql.AnalysisException: cannot resolve 'to_binary('abc', 1)' due to data type mismatch: Unsupported encoding format: Some(1). The format has to be a case-insensitive string literal of 'hex', 'utf-8', 'base2', or 'base64'; line 1 pos 7;
```
- Removed `base2` format support
```
scala> spark.sql("select to_binary('abc', 'base2')").show()
org.apache.spark.sql.AnalysisException: cannot resolve 'to_binary('abc', 'base2')' due to data type mismatch: Unsupported encoding format: Some(base2). The format has to be a case-insensitive string literal of 'hex', 'utf-8', or 'base64'; line 1 pos 7;
```
### How was this patch tested?
Unit test.
Closes apache#35533 from xinrong-databricks/to_binary_followup.
Authored-by: Xinrong Meng <[email protected]>
Signed-off-by: Wenchen Fan <[email protected]>
### What changes were proposed in this pull request? This PR propose to materialize `QueryPlan#subqueries` and pruned by `PLAN_EXPRESSION` on searching to improve the SQL compile performance. ### Why are the changes needed? We found a query in production that cost lots of time in optimize phase (also include AQE optimize phase) when enable DPP, the SQL pattern likes ``` select <cols...> from a left join b on a.<col> = b.<col> left join c on b.<col> = c.<col> left join d on c.<col> = d.<col> left join e on d.<col> = e.<col> left join f on e.<col> = f.<col> left join g on f.<col> = g.<col> left join h on g.<col> = h.<col> ... ``` SPARK-36444 significantly reduces the optimize time (exclude AQE phase), see detail at apache#35431, but there are still lots of time costs in `InsertAdaptiveSparkPlan` on AQE optimize phase. Before this change, the query costs 658s, after this change only costs 65s. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing UTs. Closes apache#35438 from pan3793/subquery. Authored-by: Cheng Pan <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
…onvertible
### What changes were proposed in this pull request?
Currently spark sql
```
INSERT OVERWRITE DIRECTORY 'path'
STORED AS PARQUET
query
```
can't be converted to use InsertIntoDataSourceCommand, still use Hive SerDe to write data, this cause we can't use feature provided by new parquet/orc version, such as zstd compress.
```
spark-sql> INSERT OVERWRITE DIRECTORY 'hdfs://nameservice/user/hive/warehouse/test_zstd_dir'
> stored as parquet
> select 1 as id;
[Stage 5:> (0 + 1) / 1]22/02/15 16:49:31 WARN TaskSetManager: Lost task 0.0 in stage 5.0 (TID 5, ip-xx-xx-xx-xx, executor 21): org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.IllegalArgumentException: No enum constant parquet.hadoop.metadata.CompressionCodecName.ZSTD
at org.apache.hadoop.hive.ql.io.HiveFileFormatUtils.getHiveRecordWriter(HiveFileFormatUtils.java:249)
at org.apache.spark.sql.hive.execution.HiveOutputWriter.<init>(HiveFileFormat.scala:123)
at org.apache.spark.sql.hive.execution.HiveFileFormat$$anon$1.newInstance(HiveFileFormat.scala:103)
at org.apache.spark.sql.execution.datasources.SingleDirectoryDataWriter.newOutputWriter(FileFormatDataWriter.scala:120)
at org.apache.spark.sql.execution.datasources.SingleDirectoryDataWriter.<init>(FileFormatDataWriter.scala:108)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:269)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:203)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:202)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
```
### Why are the changes needed?
Convert InsertIntoHiveDirCommand to InsertIntoDataSourceCommand can support more features of parquet/orc
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes apache#35528 from AngersZhuuuu/SPARK-38215.
Authored-by: Angerszhuuuu <[email protected]>
Signed-off-by: Wenchen Fan <[email protected]>
…r query stage in AQE
### What changes were proposed in this pull request?
Match `QueryStageExec` during collecting subqeries in ExplainUtils
### Why are the changes needed?
ExplainUtils have not catched QueryStageExec during collecting subquries. So we can not get the subqueries formatted explain who is under the QueryStageExec.
Note that, it also affects the subquery of dpp.
An example to see the issue
```scala
spark.sql("CREATE TABLE t USING PARQUET AS SELECT 1 AS c")
val df = spark.sql("SELECT count(s) FROM (SELECT (SELECT c FROM t) AS s)")
df.explain("formatted")
df.collect
df.explain("formatted")
```
### Does this PR introduce _any_ user-facing change?
yes, after fix, user can see all subquries in AQE.
### How was this patch tested?
Add test
Closes apache#35544 from ulysses-you/SPARK-38232.
Authored-by: ulysses-you <[email protected]>
Signed-off-by: Wenchen Fan <[email protected]>
…solved nodes ### What changes were proposed in this pull request? Skip nodes whose children have not been resolved yet within `GetDateFieldOperations`. ### Why are the changes needed? The current `GetDateFieldOperations` could result in `org.apache.spark.sql.catalyst.analysis.UnresolvedException: Invalid call to dataType on unresolved object` in some cases. See the example added in unit test. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Added a unit test. Closes apache#35568 from Ngone51/SPARK-35937-followup. Authored-by: yi.wu <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
… DB2 dialect ### What changes were proposed in this pull request? This PR follows up apache#35166. The previously referenced DB2 documentation is incorrect, resulting in the lack of compile that supports some aggregate functions. The correct documentation is https://www.ibm.com/docs/en/db2/11.5?topic=af-regression-functions-regr-avgx-regr-avgy-regr-count ### Why are the changes needed? Make build-in DB2 dialect support complete aggregate push-down more aggregate functions. ### Does this PR introduce _any_ user-facing change? 'Yes'. Users could use complete aggregate push-down with build-in DB2 dialect. ### How was this patch tested? New tests. Closes apache#35520 from beliefer/SPARK-37867_followup. Authored-by: Jiaan Geng <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
### What changes were proposed in this pull request? Field Id is a native field in the Parquet schema (https://github.com/apache/parquet-format/blob/master/src/main/thrift/parquet.thrift#L398) After this PR, when the requested schema has field IDs, Parquet readers will first use the field ID to determine which Parquet columns to read if the field ID exists in Spark schema, before falling back to match using column names. This PR supports: - Vectorized reader - parquet-mr reader ### Why are the changes needed? It enables matching columns by field id for supported DWs like iceberg and Delta. Specifically, it enables easy conversion from Iceberg (which uses field ids by name) to Delta, and allows `id` mode for Delta [column mapping](https://docs.databricks.com/delta/delta-column-mapping.html) ### Does this PR introduce _any_ user-facing change? This PR introduces three new configurations: `spark.sql.parquet.fieldId.write.enabled`: If enabled, Spark will write out native field ids that are stored inside StructField's metadata as `parquet.field.id` to parquet files. This configuration is default to `true`. `spark.sql.parquet.fieldId.read.enabled`: If enabled, Spark will attempt to read field ids in parquet files and utilize them for matching columns. This configuration is default to `false`, so Spark could maintain its existing behavior by default. `spark.sql.parquet.fieldId.read.ignoreMissing`: if enabled, Spark will read parquet files that do not have any field ids, while attempting to match the columns by id in Spark schema; nulls will be returned for spark columns without a match. This configuration is default to `false`, so Spark could alert the user in case field id matching is expected but parquet files do not have any ids. ### How was this patch tested? Existing tests + new unit tests. Closes apache#35385 from jackierwzhang/SPARK-38094-field-ids. Authored-by: jackierwzhang <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
…st" under ANSI mode ### What changes were proposed in this pull request? Change Cast.toString as "cast" instead of "ansi_cast" under ANSI mode. This is to restore the behavior before apache#27608 ### Why are the changes needed? 1. There is no such a function "ansi_cast" in Spark SQL 2. Add/Divide/.. has different behavior under ANSI mode as well, but they don't have this special string representation. 3. As we are setting up new Github job for ANSI mode, this can avoid test failures from TPCDS plan stability test suites ### Does this PR introduce _any_ user-facing change? Yes but quite minor, the string output of `Cast` under ANSI mode becomes "cast" instead of "ansi_cast" again. ### How was this patch tested? Existing UT Closes apache#35570 from gengliangwang/revert-SPARK-30863. Authored-by: Gengliang Wang <[email protected]> Signed-off-by: Gengliang Wang <[email protected]>
…old error message logic
### What changes were proposed in this pull request?
This PR replaces incorrect usage of `str.join` on a `List[float]` in `LogisticRegression.getThreshold`.
### Why are the changes needed?
To avoid unexpected failure if method is used in case of multi-class classification.
After this change, the following code:
```python
from pyspark.ml.classification import LogisticRegression
LogisticRegression(thresholds=[1.0, 2.0, 3.0]).getThreshold()
```
raises
```python
Traceback (most recent call last):
Input In [4] in <module>
model.getThreshold()
File /path/to/spark/python/pyspark/ml/classification.py:999 in getThreshold
raise ValueError(
ValueError: Logistic Regression getThreshold only applies to binary classification, but thresholds has length != 2. thresholds: [1.0, 2.0, 3.0]
```
instead of current
```python
Traceback (most recent call last):
Input In [7] in <module>
model.getThreshold()
File /path/to/spark/python/pyspark/ml/classification.py:1003 in getThreshold
+ ",".join(ts)
TypeError: sequence item 0: expected str instance, float found
```
### Does this PR introduce _any_ user-facing change?
No. Bugfix.
### How was this patch tested?
Manual testing.
Closes apache#35558 from zero323/SPARK-38243.
Authored-by: zero323 <[email protected]>
Signed-off-by: Sean Owen <[email protected]>
…lated to RocksDB ### What changes were proposed in this pull request? The main change of this pr as follows: 1. Refactor `KVUtils` to let the `open` method can use the passed `conf` to construct the corresponding `KVStore` 2. Use new `KVUtils#open` to add UTs related to `RocksDB`, the new UTs cover the scenarios `LevelDB` has tested. ### Why are the changes needed? Add more test scenarios related to `RocksDB`. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GA and add new UTs Closes apache#35563 from LuciferYang/kvutils-open. Authored-by: yangjie01 <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]>
This reverts commit f33e371.
### What changes were proposed in this pull request? This PR proposes migration of type hints for `pyspark.rdd` from stub file to inline annotation. ### Why are the changes needed? As a part of ongoing process of migration of stubs to inline hints. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests + new data tests. Closes apache#35252 from zero323/SPARK-37154. Authored-by: zero323 <[email protected]> Signed-off-by: zero323 <[email protected]>
### What changes were proposed in this pull request? This PR migrates type `pyspark.mllib.util` annotations from stub file to inline type hints. ### Why are the changes needed? Part of ongoing migration of type hints. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Part of ongoing migration of type hints. Closes apache#35532 from zero323/SPARK-37428. Authored-by: zero323 <[email protected]> Signed-off-by: zero323 <[email protected]>
…tusStore#replaceLogUrls` method signature ### What changes were proposed in this pull request? This pr is a followup of SPARK-38175 to remove `urlPattern` from `HistoryAppStatusStore#replaceLogUrls` method signature ### Why are the changes needed? Cleanup unused symbol. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GA Closes apache#35567 from LuciferYang/SPARK-38175-FOLLOWUP. Authored-by: yangjie01 <[email protected]> Signed-off-by: Sean Owen <[email protected]>
### What changes were proposed in this pull request? This pr aims to cleanup unused ·`private methods/fields`. ### Why are the changes needed? Code clean. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass GA Closes apache#35566 from LuciferYang/never-used. Authored-by: yangjie01 <[email protected]> Signed-off-by: Sean Owen <[email protected]>
### What changes were proposed in this pull request? Alignment between the documentation and the code. ### Why are the changes needed? The [actual default value ](https://github.com/apache/spark/blame/master/core/src/main/scala/org/apache/spark/internal/config/History.scala#L198) for `spark.history.custom.executor.log.url.applyIncompleteApplication` is `true` and not `false` as stated in the documentation. ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? Closes apache#35577 from itayB/doc. Authored-by: Itay Bittan <[email protected]> Signed-off-by: Yuming Wang <[email protected]>
…vulnerabilities ### What changes were proposed in this pull request? This PR ported HIVE-21498, HIVE-25098 and upgraded libthrift to 0.16.0. The CHANGES list for libthrift 0.16.0 is available at: https://github.com/apache/thrift/blob/v0.16.0/CHANGES.md ### Why are the changes needed? To address [CVE-2020-13949](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-13949). ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing test. Closes apache#34362 from wangyum/SPARK-37090. Lead-authored-by: Yuming Wang <[email protected]> Co-authored-by: Yuming Wang <[email protected]> Signed-off-by: Sean Owen <[email protected]>
Current GitHub workflow job **Linters, licenses, dependencies and documentation generation** is missing R packages to complete Documentation and API build. **Build and test** - is not failing as these packages are installed on the base image. We need to keep them in-sync IMO with the base image for easy switch back to ubuntu runner when ready. Reference: [**The base image**](https://hub.docker.com/layers/dongjoon/apache-spark-github-action-image/20220207/images/sha256-af09d172ff8e2cbd71df9a1bc5384a47578c4a4cc293786c539333cafaf4a7ce?context=explore) ### What changes were proposed in this pull request? Adding missing packages to the workflow file ### Why are the changes needed? To make them inline with the base image config and make the job task **complete** for standalone execution (i.e. without this image) ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? GitHub builds and in the local Docker containers Closes apache#35583 from khalidmammadov/sync_doc_build_with_base. Authored-by: khalidmammadov <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
…tter of its path is slash in create/alter table ### What changes were proposed in this pull request? After apache#28527, we change to create table under the database location when the table location is relative. However the criteria to determine if a table location is relative/absolute is `URI.isAbsolute`, which basically checks if the table location URI has a scheme defined. So table URIs like `/table/path` are treated as relative and the scheme and authority of the database location URI are used to create the table. For example, when the database location URI is `s3a://bucket/db`, the table will be created at `s3a://bucket/table/path`, while it should be created under the file system defined in `SessionCatalog.hadoopConf` instead. This change fixes that by treating table location as absolute when the first letter of its path is slash. This also applies to alter table. ### Why are the changes needed? This is to fix the behavior described above. ### Does this PR introduce _any_ user-facing change? Yes. When users try to create/alter a table with a location that starts with a slash but without a scheme defined, the table will be created under/altered to the file system defined in `SessionCatalog.hadoopConf`, instead of the one defined in the database location URI. ### How was this patch tested? Updated unit tests. Closes apache#35462 from bozhang2820/spark-31709. Authored-by: Bo Zhang <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
…ime window / session window ### What changes were proposed in this pull request? This PR proposes to apply strict nullability of nested column in window struct for both time window and session window, which respects the dataType of TimeWindow and SessionWindow. ### Why are the changes needed? The implementation of rule TimeWindowing and SessionWindowing have been exposed the possible risks of inconsistency between the dataType of TimeWindow/SessionWindow and the replacement. For the replacement, it is possible that analyzer/optimizer may decide the value expressions to be non-nullable. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? New tests added. Closes apache#35543 from HeartSaVioR/SPARK-38227. Authored-by: Jungtaek Lim <[email protected]> Signed-off-by: Liang-Chi Hsieh <[email protected]>
### What changes were proposed in this pull request? Adds `scale` parameter to `floor`/`ceil` functions in order to allow users to control the rounding position. This feature is proposed in the PR: apache#34593 ### Why are the changes needed? Currently we support Decimal RoundingModes : HALF_UP (round) and HALF_EVEN (bround). But we have use cases that needs RoundingMode.UP and RoundingMode.DOWN. Floor and Ceil functions helps to do this but it doesn't support the position of the rounding. Adding scale parameter to the functions would help us control the rounding positions. Snowflake supports `scale` parameter to `floor`/`ceil` : ` FLOOR( <input_expr> [, <scale_expr> ] )` REF: https://docs.snowflake.com/en/sql-reference/functions/floor.html ### Does this PR introduce _any_ user-facing change? Now users can pass `scale` parameter to the `floor` and `ceil` functions. ``` > SELECT floor(-0.1); -1.0 > SELECT floor(5); 5 > SELECT floor(3.1411, 3); 3.141 > SELECT floor(3.1411, -3); 1000.0 > SELECT ceil(-0.1); 0.0 > SELECT ceil(5); 5 > SELECT ceil(3.1411, 3); 3.142 > SELECT ceil(3.1411, -3); 1000.0 ``` ### How was this patch tested? This patch was tested locally using unit test and git workflow. Closes apache#34729 from sathiyapk/SPARK-37475-floor-ceil-scale. Authored-by: Sathiya KUMAR <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
… not consistent with the values due to time zone difference ### What changes were proposed in this pull request? Currently timestamp column's stats (min/max) are stored using UTC time zone in metastore, and when desc its min/max column stats, they are also shown in UTC. As a result, for users not in UTC, the column stats (shown to users) are not consistent with the actual value, which causes confusion. Note that it does not affect correctness. But we'd better to remove confusion for users. ### Why are the changes needed? To make column stats and column value consistent when shown to users. ### Does this PR introduce _any_ user-facing change? As an example: ``` spark-sql> create table tab_ts_master (ts timestamp) using parquet; spark-sql> insert into tab_ts_master values make_timestamp(2022, 1, 1, 0, 0, 1.123456), make_timestamp(2022, 1, 3, 0, 0, 2.987654); spark-sql> select * from tab_ts_master; 2022-01-01 00:00:01.123456 2022-01-03 00:00:02.987654 spark-sql> set spark.sql.session.timeZone; spark.sql.session.timeZone Asia/Shanghai spark-sql> analyze table tab_ts_master compute statistics for all columns; ``` Before this change: ``` spark-sql> desc formatted tab_ts_master ts; col_name ts data_type timestamp comment NULL min 2021-12-31 16:00:01.123456 max 2022-01-02 16:00:02.987654 num_nulls 0 distinct_count 2 avg_col_len 8 max_col_len 8 histogram NULL ``` The min/max column stats are inconsistent with what the user sees in the column values. After this change: ``` spark-sql> desc formatted tab_ts ts; col_name ts data_type timestamp comment NULL min 2022-01-01 00:00:01.123456 max 2022-01-03 00:00:02.987654 num_nulls 0 distinct_count 2 avg_col_len 8 max_col_len 8 histogram NULL ``` ### How was this patch tested? Added new unit tests. Closes apache#35440 from wzhfy/desc_ts_timeZones. Authored-by: Zhenhua Wang <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
…d of Abs/CheckOverflow ### What changes were proposed in this pull request? Hide the "failOnError" field in the toString method of Abs/CheckOverflow. Here are two examples: * Abs.toString: `abs(-1, true)` => `abs(-1)` * CheckOverflow.toString: `CheckOverflow(0.12, DecimalType(5, 3), true)` => `CheckOverflow(0.12, DecimalType(5, 3))` ### Why are the changes needed? After changes, over 200 test failures of *PlanStabilitySuite are fixed with ANSI mode on. This is important for setting up testing job for ANSI mode. Also, having the "failOnError" field in the string output of Abs, e.g. `abs(-1, true)`, is quite odd. ### Does this PR introduce _any_ user-facing change? Yes but quite minor, hiding the "failOnError" field in the toString method of Abs/CheckOverflow ### How was this patch tested? Manual turn on ANSI mode and test all the *PlanStabilitySuite Closes apache#35590 from gengliangwang/fixStabilitySuite. Authored-by: Gengliang Wang <[email protected]> Signed-off-by: Gengliang Wang <[email protected]>
### What changes were proposed in this pull request? This pr aims to upgarde `scalatestplus-mockito` from 3.2.110.0 to 3.2.11.0 and the actual `mockito` is upgraded from 3.12 to 4.2.0 ### Why are the changes needed? Upgrade `scalatestplus-mockito` and the changes of actually used `mockito` as follows: - https://github.com/mockito/mockito/releases/tag/v4.0.0 - https://github.com/mockito/mockito/releases/tag/v4.1.0 - https://github.com/mockito/mockito/releases/tag/v4.2.0 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GA Closes apache#35579 from LuciferYang/upgrade-mockito-42. Authored-by: yangjie01 <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
### What changes were proposed in this pull request? This PR migrates type `pyspark.mllib.tree` annotations from stub file to inline type hints. ### Why are the changes needed? Part of ongoing migration of type hints. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests. Closes apache#35545 from zero323/SPARK-37427. Authored-by: zero323 <[email protected]> Signed-off-by: zero323 <[email protected]>
### What changes were proposed in this pull request? q83 has a different plan output under ANSI mode. Because of the ANSI type coercion, it can actually push down a `IN` predicate into Parquet data source. The following screenshot contains all the differences between default plan(left) and ansi plan(right): <img width="1400" alt="Screen Shot 2022-02-21 at 7 05 46 PM" src="https://user-images.githubusercontent.com/1097932/154945698-be57bed8-b4a4-492a-a85b-9a538e518720.png"> This PR is to add approved TPCDS plans under ANSI mode so that we can set up a new job to run tests with ANSI mode on. ### Why are the changes needed? For passing TPCDS plan stability tests under ANSI mode. We are going to set up a new job to run tests with ANSI mode on https://issues.apache.org/jira/browse/SPARK-38154 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Manually turn on ANSI mode and run tests and check whether all the plan stability tests passed. Closes apache#35598 from gengliangwang/fixMoreStability. Authored-by: Gengliang Wang <[email protected]> Signed-off-by: Gengliang Wang <[email protected]>
{kind=link}
### What changes were proposed in this pull request? This PR adds the following options to mypy configuration ``` warn_unused_ignores = True warn_redundant_casts = True ``` ### Why are the changes needed? This ensures that no unused casts and imports are used to reduce overall noise. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes apache#35740 from zero323/SPARK-38424. Authored-by: zero323 <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
…ntDecimal ### What changes were proposed in this pull request? In `NTile`, the number of rows per bucket is computed as `n / buckets`, where `n` is the partition size, and `buckets` is the argument to `NTile` (number of buckets). The code currently casts the arguments to IntDecimal, then casts the result back to IntegerType. This is unnecessary, since it is equivalent to just doing integer division, i.e. `n div buckets`. This PR makes that simplifying change. ### Why are the changes needed? Simplifies the code, and avoids a couple of casts at run-time. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Relying on existing tests (specifically, org.apache.spark.sql.hive.execution.WindowQuerySuite). Closes apache#35863 from cashmand/remove_decimal_cast. Authored-by: cashmand <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
### What changes were proposed in this pull request? UnsafeHashedRelation should serialize numKeys out ### Why are the changes needed? One case I found was this: We turned on ReusedExchange(BroadcastExchange), but the returned UnsafeHashedRelation is missing numKeys. The reason is that the current type of TorrentBroadcast._value is SoftReference, so the UnsafeHashedRelation obtained by deserialization loses numKeys, which will lead to incorrect calculation results. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added a line of assert to an existing unit test Closes apache#35836 from mcdull-zhang/UnsafeHashed. Authored-by: mcdull-zhang <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
### What changes were proposed in this pull request? This PR upgrade Py4J 0.10.9.4, with relevant documentation changes. ### Why are the changes needed? Py4J 0.10.9.3 has a resource leak issue when pinned thread mode is enabled - it's enabled by default in PySpark at apache@41af409. We worked around this by enforcing users to use `InheritableThread` or `inhteritable_thread_target` as a workaround. After upgrading, we don't need to enforce users anymore because it automatically cleans up, see also py4j/py4j#471 ### Does this PR introduce _any_ user-facing change? Yes, users don't have to use `InheritableThread` or `inhteritable_thread_target` to avoid resource leaking problem anymore. ### How was this patch tested? CI in this PR should test it out. Closes apache#35871 from HyukjinKwon/SPARK-38563. Authored-by: Hyukjin Kwon <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
### What changes were proposed in this pull request? Migrate the following errors in QueryExecutionErrors onto use error classes as INVALID_SQL_SYNTAX: - functionNameUnsupportedError - showFunctionsUnsupportedError - showFunctionsInvalidPatternError - createFuncWithBothIfNotExistsAndReplaceError - defineTempFuncWithIfNotExistsError - unsupportedFunctionNameError - specifyingDBInCreateTempFuncError - invalidNameForDropTempFunc ### Why are the changes needed? Porting parsing errors of functions to new error framework. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? UT added. Closes apache#35865 from ivoson/SPARK-38106. Lead-authored-by: Tengfei Huang <[email protected]> Co-authored-by: Huang Tengfei <[email protected]> Signed-off-by: Max Gekk <[email protected]>
### What changes were proposed in this pull request? Add a new config to set the memory overhead factor for drivers and executors. Currently the memory overhead is hard coded to 10% (except in Kubernetes), and the only way to set it higher is to set it to a specific memory amount. ### Why are the changes needed? In dynamic environments where different people or use cases need different memory requirements, it would be helpful to set a higher memory overhead factor instead of having to set a higher specific memory overhead value. The kubernetes resource manager already makes this configurable. This makes it configurable across the board. ### Does this PR introduce _any_ user-facing change? No change to default behavior, just adds a new config users can change. ### How was this patch tested? New UT to check the memory calculation. Closes apache#35504 from Kimahriman/yarn-configurable-memory-overhead-factor. Authored-by: Adam Binford <[email protected]> Signed-off-by: Thomas Graves <[email protected]>
Try and get the time from the queue if it's defined for when the exec was requested. Add requestTs to the ExecutorData Core tests compile, not really tested yet though Add more tests Add some comments explaining the logic and also the amortized cost of the queue ops. There is no exec request time with the local sched backend since we don't really have an exec request time. Test the request times are set for both default profile and custom resource profile. Handle nulls in ExecutorInfo hashing. Add old constructor for ExecutorInfo for src/bin compat. Back out unrelated test changes to verify the legacy constructor is called, update the JSON protocol suite to validate we store/deserialize the request time info, syncrhonize some access to requestedTotalExecutorsPerResourceProfile CR feedback, check if times is empty rather than hanlding an exception.
This reverts commit 85a3f9d5dab1cdfd55cc3816861e0b524d1590b9.
ad8e8f7 to
603ba97
Compare
holdenk
pushed a commit
that referenced
this pull request
Apr 1, 2024
…n properly
### What changes were proposed in this pull request?
Make `ResolveRelations` handle plan id properly
### Why are the changes needed?
bug fix for Spark Connect, it won't affect classic Spark SQL
before this PR:
```
from pyspark.sql import functions as sf
spark.range(10).withColumn("value_1", sf.lit(1)).write.saveAsTable("test_table_1")
spark.range(10).withColumnRenamed("id", "index").withColumn("value_2", sf.lit(2)).write.saveAsTable("test_table_2")
df1 = spark.read.table("test_table_1")
df2 = spark.read.table("test_table_2")
df3 = spark.read.table("test_table_1")
join1 = df1.join(df2, on=df1.id==df2.index).select(df2.index, df2.value_2)
join2 = df3.join(join1, how="left", on=join1.index==df3.id)
join2.schema
```
fails with
```
AnalysisException: [CANNOT_RESOLVE_DATAFRAME_COLUMN] Cannot resolve dataframe column "id". It's probably because of illegal references like `df1.select(df2.col("a"))`. SQLSTATE: 42704
```
That is due to existing plan caching in `ResolveRelations` doesn't work with Spark Connect
```
=== Applying Rule org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations ===
'[apache#12]Join LeftOuter, '`==`('index, 'id) '[apache#12]Join LeftOuter, '`==`('index, 'id)
!:- '[apache#9]UnresolvedRelation [test_table_1], [], false :- '[apache#9]SubqueryAlias spark_catalog.default.test_table_1
!+- '[apache#11]Project ['index, 'value_2] : +- 'UnresolvedCatalogRelation `spark_catalog`.`default`.`test_table_1`, [], false
! +- '[apache#10]Join Inner, '`==`('id, 'index) +- '[apache#11]Project ['index, 'value_2]
! :- '[#7]UnresolvedRelation [test_table_1], [], false +- '[apache#10]Join Inner, '`==`('id, 'index)
! +- '[#8]UnresolvedRelation [test_table_2], [], false :- '[apache#9]SubqueryAlias spark_catalog.default.test_table_1
! : +- 'UnresolvedCatalogRelation `spark_catalog`.`default`.`test_table_1`, [], false
! +- '[#8]SubqueryAlias spark_catalog.default.test_table_2
! +- 'UnresolvedCatalogRelation `spark_catalog`.`default`.`test_table_2`, [], false
Can not resolve 'id with plan 7
```
`[#7]UnresolvedRelation [test_table_1], [], false` was wrongly resolved to the cached one
```
:- '[apache#9]SubqueryAlias spark_catalog.default.test_table_1
+- 'UnresolvedCatalogRelation `spark_catalog`.`default`.`test_table_1`, [], false
```
### Does this PR introduce _any_ user-facing change?
yes, bug fix
### How was this patch tested?
added ut
### Was this patch authored or co-authored using generative AI tooling?
ci
Closes apache#45214 from zhengruifeng/connect_fix_read_join.
Authored-by: Ruifeng Zheng <[email protected]>
Signed-off-by: Dongjoon Hyun <[email protected]>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Try and get the time from the queue if it's defined for when the exec was requested.
Add requestTs to the ExecutorData
Core tests compile, not really tested yet though
Add more tests
Add some comments explaining the logic and also the amortized cost of the queue ops.
There is no exec request time with the local sched backend since we don't really have an exec request time.
Test the request times are set for both default profile and custom resource profile. Handle nulls in ExecutorInfo hashing.
Add old constructor for ExecutorInfo for src/bin compat.
Back out unrelated test changes to verify the legacy constructor is called, update the JSON protocol suite to validate we store/deserialize the request time info, syncrhonize some access to requestedTotalExecutorsPerResourceProfile
CR feedback, check if times is empty rather than hanlding an exception.
What changes were proposed in this pull request?
Why are the changes needed?
Does this PR introduce any user-facing change?
How was this patch tested?